Executive Summary – Overview
Deep neural networks have been shown to be fooled rather easily using adversarial attack algorithms. Practical methods such as adversarial patches have been shown to be extremely effective in causing misclassification. How- ever, these patches are highlighted using standard network interpretation algorithms, thus revealing the identity of the adversary. We show that it is possible to create adversarial patches which not only fool the prediction, but also change what we interpret regarding the cause of the prediction. Moreover, we introduce our attack as a controlled setting to measure the accuracy of interpretation algorithms. We show this using extensive experiments for Grad-CAM interpretation that transfers to occluding patch interpretation as well. We believe our algorithms can facilitate developing more robust network interpretation tools that truly explain the network’s underlying decision making process.
Technical Challenge/Activities
Deep learning has achieved great results in many domains including computer vision. However, it is still far from being deployed in many real-world applications due to reasons including:
Explainable AI (XAI): Explaining the prediction of deep neural networks is a challenging task because they are complex models with large number of parameters. Recently, XAI has become a trending research area in which the goal is to develop reliable interpretation algorithms that explain the underlying decision making process. Designing such algorithms is a challenging task and considerable work has been done to describe local explanations – explaining the model’s output for a given input.
Adversarial examples: It has been shown that deep neural networks are vulnerable to adversarial examples. These carefully constructed samples are created by adding imperceptible perturbations to the original input for changing the final decision of the network. This is important for two reasons: (a) Such vulnerabilities could be used by adversaries to fool AI algorithms when they are deployed in real-world applications such as Internet of Things (IoT) or self-driving cars (b) Studying these attacks can lead to better understanding of how deep neural networks work and also possibly better generalization. In this research, we design adversarial attack algorithms that not only fool the network prediction but also fool the network interpretation. Our main goal is to utilize such attacks as a tool to investigate the reliability of network interpretation algorithms. Moreover, since our attacks fool the network interpretation, they can be seen as a potential vulnerability in the applications that utilize network interpretation to understand the cause of the prediction (e.g., in health-care applications.)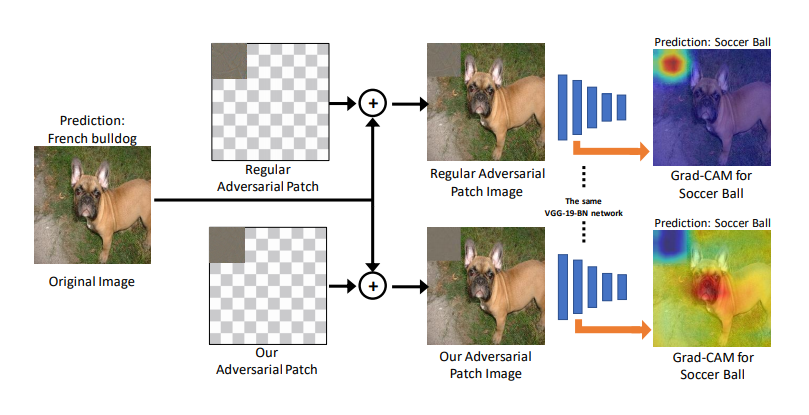
Reliability of network interpretation: We are interested in studying the reliability of the interpretation in highlighting true cause of the prediction. To this end, we use the adversarial patch method to design a controlled adversarial attack setting where the adversary changes the network prediction by manipulating only a small region of the image. Hence, we know that the cause of the wrong prediction should be inside the patch. We show that it is possible to optimize for an adversarial patch that attacks the prediction without being highlighted by the interpretation algorithm as the cause of the wrong prediction.
Potential Impact
We introduce adversarial patches which fool both the classifier and the interpretation of the resulting category. Since we know that the patch is the true cause of the wrong prediction, a reliable interpretation algorithm should definitely highlight the patch region. We successfully design an adversarial patch that does not get highlighted in the interpretation and hence show that popular interpretation algorithms are not highlighting the true cause of the prediction. Our work suggests that the community needs to develop more robust interpretation algorithms.
Project Members
UMBC Faculty: Dr. Hamed Pirsiavash
Students: Akshayvarun Subramanya,Vipin Pillai
Sponsor
This work was performed under the following financial assistance award: 60NANB18D279 from U.S. Department of Commerce, National Institute of Standards and Technology, funding from SAP SE, and also NSF grant 1845216.